Low Stable-Rank Structure in LoRA-DPO Adapters on Pythia 70M–1B: Empirical Scaling and Formal Invariants
We made a model four times bigger. The adapter stable rank stayed the same — under this recipe, on this dataset.
When you fine-tune a language model with LoRA under Direct Preference Optimization, the adapter learns to move in a tiny number of directions — roughly 3 to 4, across Pythia models from 70M to 1B parameters, trained on hh-rlhf with a fixed LoRA configuration. We call this width-stable low-rank structure under fixed recipe. The observed floor appears consistent with the preference signal complexity, though we have not varied the dataset or LoRA configuration to isolate causes.
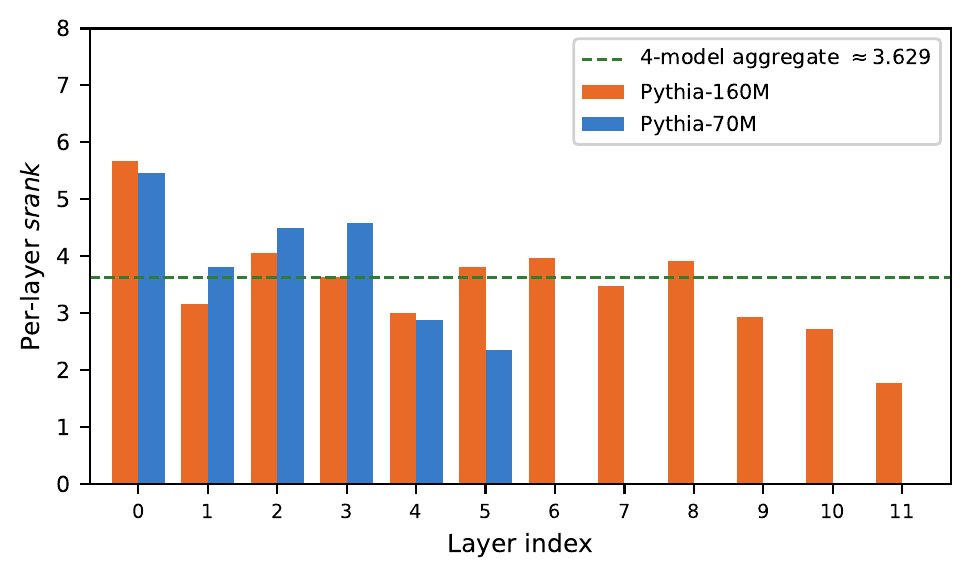
Each dot is one model. Hover for exact values. The dashed line is the empirical floor at srank ≈ 3.6. A random LoRA matrix at r=128 would have srank ≈ 128 — these adapters are ~35× lower-dimensional.
across all models
with no geometry change
alignment (γ signal)
Background
What does “stable rank 3.6” mean?
A LoRA adapter is a matrix — a grid of numbers that shifts a weight in the model. That matrix can be “wide” (spread across many directions in space) or “narrow” (concentrated in just a few). Stable rank measures this width: a value of 3.6 means the adapter’s energy is effectively spread across ~3–4 directions, even though the matrix formally has 128 dimensions.
Think of a ship’s rudder. The ship is enormous. The rudder is tiny. But the rudder has one job — deflect the flow — and it does that job in a small number of geometric directions. Our finding: DPO always uses a “rudder” of about 3–4 directions, no matter how large the ship.
Key Finding
DPO and CLM find the same directions
Here is the second surprise. When we train on preference data (DPO) vs. plain language modelling (CLM), we get different adapters — but their top singular vectors overlap far more than chance. We call this the γ-rudder signal.
The chart below shows, for each layer of a 1B-parameter model, how much DPO and CLM agree on the important directions. A value of 3× means their top-5 singular vectors share 3× more subspace than the analytic Haar-random expectation — the closed-form baseline E[overlap] = k/d for two uniformly-random k-frames in R^d (not a sampled approximation; exact for any finite d).
Four traces: DPO and CLM at two independent seeds (42 and 117). The seeds use completely different data draws — yet the curves track closely. The signal is not a random artifact.
This alignment isn’t specific to one part of the model. It appears in all four LoRA target modules: the attention projections and both MLP layers.
What we ruled out
Three explanations that didn’t survive
Before concluding the srank floor is real, we tried to explain it away with three targeted alternatives. All three failed, though they do not exhaust the space of possible confounds.
Attempt 1: maybe it’s just the biases. If LayerNorm gain vectors (γ parameters) span the adapter’s subspace, then the geometry would be trivially determined by initialization — not preference learning. We tested this by projecting each DPO adapter onto the LayerNorm gain subspace. Result: 99.97% of the energy lies outside it. This rules out the LayerNorm-gain subspace as an explanation. It does NOT rule out a broader class of pretrained-anisotropy explanations (weight curvature, weight-tying, token-frequency bias, optimizer-induced anisotropy).
Attempt 2: maybe bias-only fine-tuning reproduces it. BitFit trains only bias parameters — no weight matrices at all. If BitFit-DPO produces the same loss reduction as LoRA-DPO, the geometric signal would be “gauge-accessible” (reachable without learning any subspace). We ran BitFit-DPO to 800 steps and beyond.
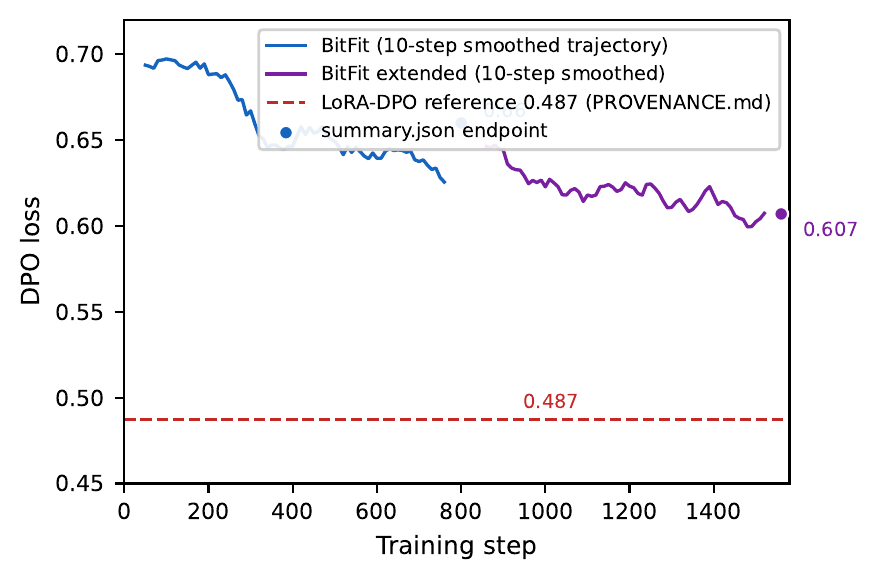
Attempt 3: maybe depth carries structure. If DPO adapters form a “quasiparticle” — a correlated pattern that travels across layers — we’d expect the layer-depth correlator $C(L, L+k)$ to decay with $k$. It doesn’t. The correlator is flat (Pearson ≈ 0.97 regardless of depth gap). No depth-wise structure. No quasiparticle.
Formal grounding
Ruling out a measurement artifact from α or r
One might worry: maybe we’re measuring an artifact of hyperparameter choice. If we change the LoRA scaling $\alpha$, does srank change?
We prove it doesn’t — formally, in Lean 4:
stableRank_smul_invariant— scaling a fixed learned matrix by any $\lambda \neq 0$ leaves srank unchangedrsLoraUpdate_frob_bounded— Frobenius energy obeys $|\Delta W|_F^2 \leq \alpha^2 c$, while srank is invariant to the scalar
The proofs use Mathlib’s linear algebra library and are machine-checked. This rules out a trivial measurement artifact: the observed srank ≈ 3.6 is not an artifact of our α setting. Important caveat: this does NOT imply that retraining with different (α, r) would converge to the same geometry. What happens when you retrain under a different configuration is an open empirical question.
See the Lean proof status →
For the curious
How the experiments work
Models. Pythia 70M, 160M, 410M, 1B (EleutherAI). Pre-trained, no instruction tuning.
LoRA. $r=128$, $\alpha=256$. Targets: query_key_value, dense, dense_h_to_4h, dense_4h_to_h. 800 training steps, LR=5e-6, cosine schedule, fp16.
Data. Anthropic/hh-rlhf, 2000 samples. DPO uses preference pairs. CLM uses chosen responses only (no rejection signal).
Reproducibility. All adapter checkpoints are mirrored at d3banjan/lazy-rudder-checkpoints (~1.9 GB). Every figure regenerates from make analysis && make paper. Per-checkpoint hashes, training configs, and seeds are recorded in PROVENANCE.md.
Reviewer M9 response
Geometry–behavior decoupling (T1.2)
We measured reward margin and KL-to-base on 495 clean held-out Anthropic/hh-rlhf test examples for all five DPO checkpoints (70M, 160M, 410M, 1B×2 seeds), β=0.1, fp16.
| Reward margin = β · [log π_θ(y_win | x)/π_ref(y_win | x) − log π_θ(y_los | x)/π_ref(y_los | x)]. KL-to-base = mean per-token log-ratio of DPO vs base on chosen response (teacher-forced; negative = DPO keeps probability close to or below base, consistent with β-regularization). |
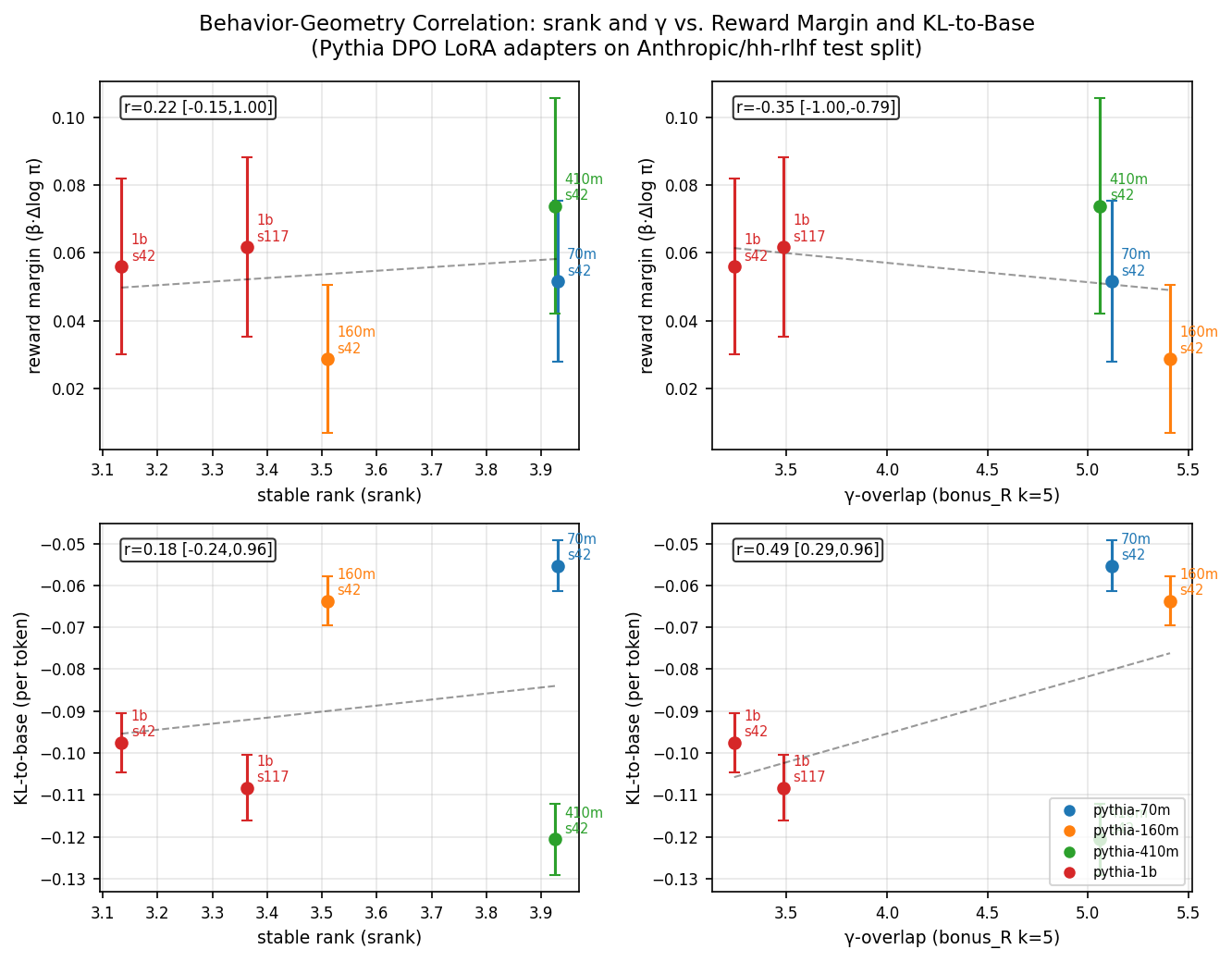
Primary finding: structural geometry and behavioral outcome are decoupled. Geometric alignment (γ) does not predict reward; it predicts KL drift. Tighter overlap with pretrained right-subspaces correlates with more divergence from the base distribution and lower reward margin — not efficient alignment. Stable rank (srank) is uncorrelated with reward margin across this scale range: it measures the rigid geometric constraint under which learning is forced to happen (the width of the pipe), not how successful that learning turns out to be. Adapters with r=128, α=256 on hh-rlhf converge to srank ≈ 3.6 regardless of model size; reward margin varies independently. This decoupling — not a confirmation of benign steering — is the paper’s primary empirical result.
Caveat. n=5 checkpoints; bootstrap CIs are wide and one pins at ±1. The most parsimonious reading of the current data is decoupling, but confirmation requires T2.1 (non-Pythia replication) and T1.3 (additional seeds).
Open question
Does the srank floor persist, or is it a transient early-training artefact?
Reviewer M7 asked whether the observed srank ≈ 3–4 at step 800 reflects convergence or just an early-training lazy regime. The right test is a srank-vs-training-step trajectory for each model size.
![[Pending] srank vs training step](/lazy-rudder-paper/assets/img/fig_F_progression.png)
save_steps ≤ 100 or a SrankCallback. See scripts/generate_fig_F.py for the data schema.What we know now. The loss curve (logged at 10-step intervals in trainer_state.json) decreases monotonically through step 800 with no plateau, suggesting training was active throughout. The srank floor is consistent across DPO and CLM objectives and across two independent seeds at 1B scale — harder to explain as a transient coincidence. These are supportive signals but not a substitute for a trajectory plot. We flag this as a Tier-1 follow-up.
Citation
Cite this work
References. Hu et al. (2022) LoRA; Rafailov et al. (2023) DPO; Kalajdzievski (2023) RsLoRA; Biderman et al. (2023) Pythia; Lean 4 + Mathlib (The Mathlib Community, 2020).